مقدمة وحقائق أساسية
قبل الغوص في تفاصيل عملية التدريب، دعونا نستعرض بعض الحقائق الأساسية:
- النموذج الأساسي المستخدم هو GPT-3.5، أحدث إصدار من نموذج GPT، وتم الانتهاء من تدريبه في بداية 2022
- تم الاعتماد على الحواسيب الفائقة لخدمة Azure AI في عملية التدريب
- تم تحسين عملية التدريب باستخدام التعلم المعزز (Reinforcement Learning)
البيانات المستخدمة في التدريب
تم استخدام ثلاث مجموعات رئيسية من البيانات:
1. مجموعة البيانات المثالية
مجموعة بيانات مكونة من أسئلة وأجوبة مثالية تم إنشاؤها من قبل مدخلي بيانات بشر.
2. مجموعة البيانات الأساس
تتكون من النصوص (أسئلة وأوامر) التي أرسلها المستخدمون لخدمات OpenAI APIs مثل:
- GPT
- InstructGPT
3. مجموعة بيانات المقارنة
مجموعة بيانات تحتوي على أسئلة مع خيارات متعددة للإجابة، تم تكوينها خلال عملية التدريب من خلال:
- تمرير بيانات الأساس على نموذج الـ SFT
- توليد عدة خيارات للإجابة لكل سؤال
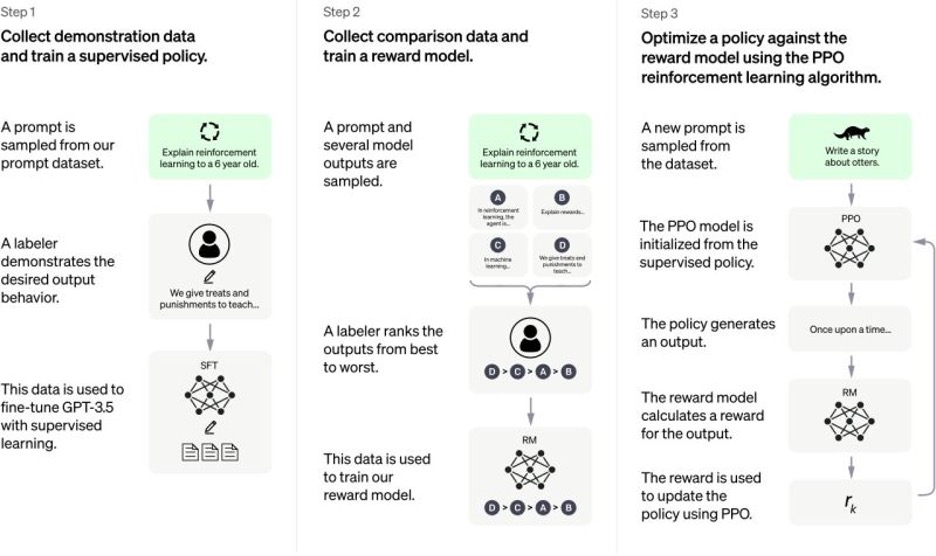
مراحل التدريب
تم تنفيذ التدريب على ثلاث مراحل رئيسية:
المرحلة الأولى: التحسين الدقيق
- إجراء fine-tuning لنموذج GPT-3.5 على مجموعة البيانات المثالية
- إنتاج نموذج الـ SFT (Supervised Fine-Tuning)
المرحلة الثانية: تدريب نموذج المكافأة
- تكوين مجموعة بيانات التقييم
- تمرير البيانات على مدخلي بيانات لتقييم الإجابات المختلفة
- استخدام التقييمات لتدريب نموذج المكافأة (Reward Model)
المرحلة الثالثة: التحسين النهائي
- استخدام جزء من مجموعة بيانات الأساس
- تطبيق خوارزمية PPO (Proximal Policy Optimization)
- الاعتماد على نموذج المكافأة المدرب في المرحلة السابقة
التحسين المستمر
تم تكرار هذه الخطوات عدة مرات للوصول إلى النموذج الحالي. يعد نشر النموذج بشكل مجاني المرحلة الأخيرة من التدريب، حيث سيتم استخدام التغذية المرجعية من الجمهور في تحسين كفاءة النموذج.
نقاط القوة الرئيسية
يتميز النموذج بثلاث نقاط قوة رئيسية:
-
النموذج الأساسي القوي
- استخدام نموذج اللغة العملاق GPT-3.5
- يعد هذا المكون الأساسي والأهم
-
جودة البيانات
- استخدام مجموعة بيانات مثالية
- تحسين ملحوظ في جودة المخرجات
-
التعلم المعزز المتقدم
- تحسين النموذج باستخدام التعلم المعزز (RL)
- الاعتماد على نموذج مكافأة مدرب وفقاً للتقييم البشري